Abstract
A LABORATORY [100] FOR THE EMPIRICAL STUDY OF MACHINE REASONING.
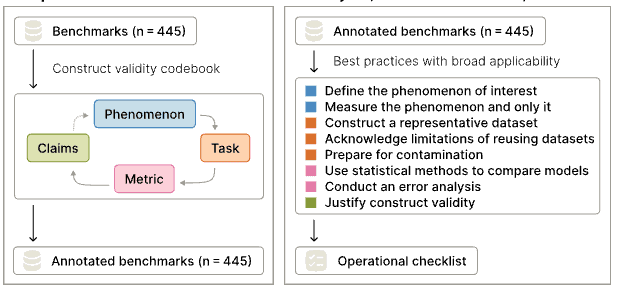
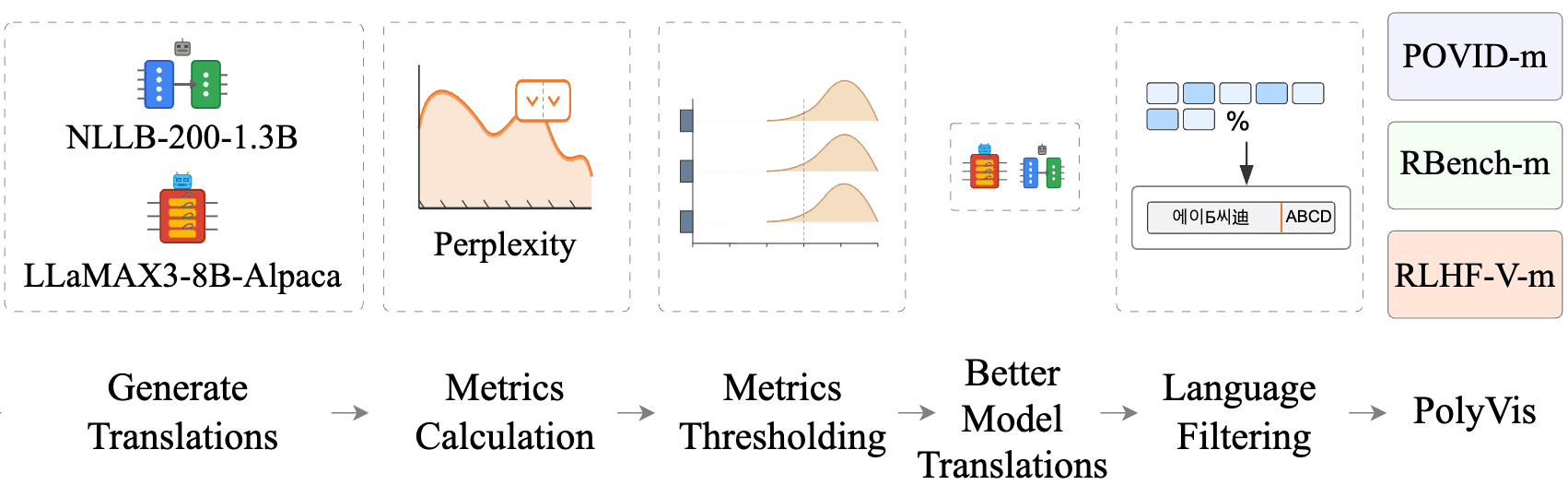
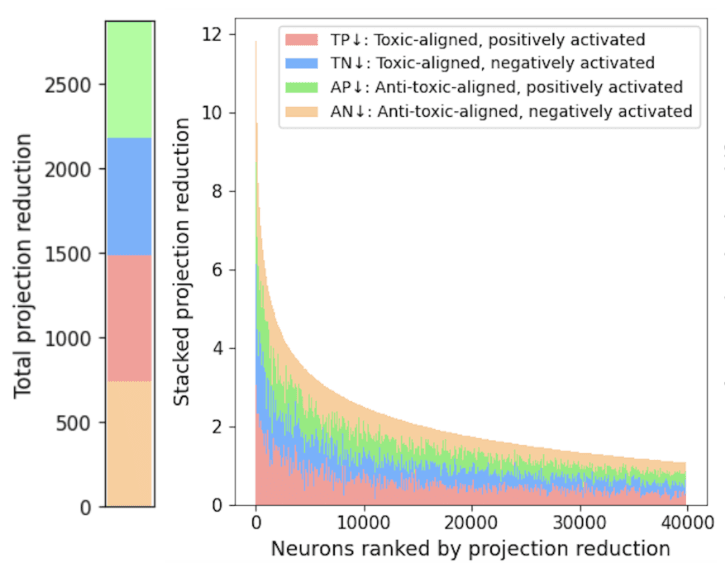
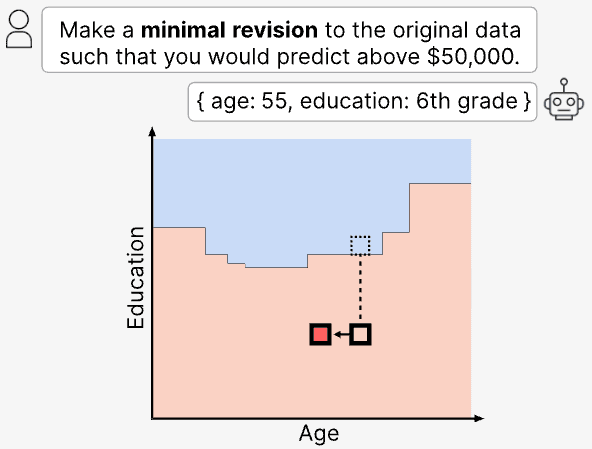
Disclosed herein is the Reasoning with Machines Lab [100], a research apparatus assembled at the University of Oxford [107] and directed by a Principal Investigator [101] overseeing a cohort [102] of DPhil and MSc students. The lab operates along four research axes [103], the outputs of which flow through a publication stream [104] and a partner channel [105].
An empirical research group at the Oxford Internet Institute. We study LLM evaluation, safety, reasoning, and the agentic systems built from them.
Inventor / PI
[101]
[101]
Prof. Adam Mahdi
Oxford Internet Institute, University of Oxford
Adam leads OxRML. The group studies how language models reason, how people work with them, and how agentic systems behave on real scientific and decision-making tasks. He won the Oxford Teaching Excellence Award in 2025.