An empirical research group at the Oxford Internet Institute. We study LLM evaluation, safety, reasoning, and the agentic systems built from them. Every paper is a cycle of plan, do, check, act: a small, deliberate experiment toward the standard we want AI evaluation, safety, and reasoning to hold.
DIRECTION
Reasoning systems that scientists, clinicians, and the public can trust, measured by what they do rather than what they claim.
Each direction is a standard the lab is working toward. Together they describe the field we want AI evaluation, safety, and reasoning to become.
01
DIRECTION · EVALUATION
Benchmarks and Evaluation
TARGET CONDITION
A field where every benchmark publishes its construct validity, and where evaluation is treated as an experimental science.
We work on the science of LLM evaluation: what benchmarks measure, where they mislead, and how to build ones that hold up.
CYCLE STATE · IN PRACTICE◯ → ◐ → ●
02
DIRECTION · SAFETY
AI Safety and Security
TARGET CONDITION
A practice of measuring real harms (bias, toxicity, agentic misalignment) at the neuron and the deployment, before they reach the public.
We work on bias, toxicity, and agentic misalignment, and on the technical and governance tools that address them.
CYCLE STATE · IN PRACTICE◯ → ◐ → ●
03
DIRECTION · AGENTIC
Agentic AI for Science
TARGET CONDITION
Scientific agents that synthesise knowledge reliably enough that a researcher can act on them, transparently enough that they can audit them.
Agentic systems for scientific work. We focus on keeping them reliable, transparent, and grounded in the domain.
CYCLE STATE · IN PRACTICE◯ → ◐ → ●
04
DIRECTION · HUMAN-AI
Human–AI Interaction
TARGET CONDITION
Decisions made with AI in healthcare, law, and policy, studied empirically rather than assumed safe because the model is impressive.
Empirical studies of how people use AI in high-stakes settings: healthcare, law, and policy.
CYCLE STATE · IN PRACTICE◯ → ◐ → ●
STEP 03 · EXPERIMENT TOWARD THE TARGET
Ten cycles, recorded.
Each paper below is one full kata cycle: target, actual, obstacle, next. The most recent carries the lacquer NOW stamp. Completed cycles carry the bamboo mark.
NOW · current cycleCOMPLETED · cycle closedREFERENCE · still cited10 OF 10 ENTRIES
Fifteen people: one sensei and fourteen practitioners. Each is introduced by what they are currently practising and what they are working toward; their role is the footnote.
先生 · SENSEI · PRINCIPAL INVESTIGATOR
Prof. Adam Mahdi
Oxford Internet Institute, University of Oxford
Adam leads OxRML. The group studies how language models reason, how people work with them, and how agentic systems behave on real scientific and decision-making tasks. He won the Oxford Teaching Excellence Award in 2025.
CURRENTLY PRACTISING
Coaching the lab’s research cycles across evaluation, safety, agentic AI, and human–AI interaction.
WORKING TOWARD
A field where AI evaluation is treated as a science, with the same care as the systems it studies.
PRACTITIONER · 01
Felix Krones
DPHIL STUDENT
CURRENTLY
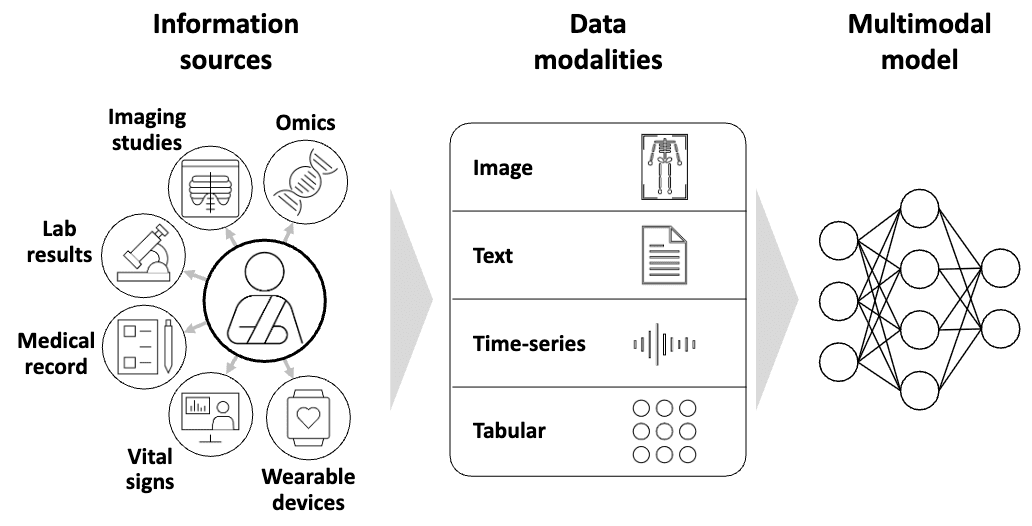
Multimodal evaluation across imaging and clinical text.
TOWARD
Digital-health systems that are measured before they are deployed.
PRACTITIONER · 02
Djavan De Clercq
DPHIL STUDENT
CURRENTLY
LLMs applied to food-security data and policy questions.
TOWARD
Decision tools for food systems that hold up under audit.
PRACTITIONER · 03
Andrew M. Bean
DPHIL STUDENT
CURRENTLY
Designing LLM evals that capture how people actually use models.
TOWARD
A standard for evaluating LLMs in genuine human contexts of use.
PRACTITIONER · 04
Yushi Yang
DPHIL STUDENT
CURRENTLY
Post-training for LLM and agentic alignment, at the neuron level.
TOWARD
Alignment interventions whose mechanism we can explain, not just observe.
PRACTITIONER · 05
Harry Mayne
DPHIL STUDENT
CURRENTLY
Interpretability and safety-relevant LLM evaluations.
TOWARD
Interpretability methods that practitioners can trust under shift.
PRACTITIONER · 06
Jessica Rodrigues
DPHIL STUDENT
CURRENTLY
Knowledge-graph methods for metascience and research synthesis.
TOWARD
Synthesis tools that scientists treat as collaborators, not search engines.
PRACTITIONER · 07
Guy Parsons
DPHIL STUDENT
CURRENTLY
Healthcare AI evaluation grounded in clinical workflow.
TOWARD
Digital-health products that earn the trust of clinicians and patients.
PRACTITIONER · 08
Karolina Korgul
DPHIL STUDENT
CURRENTLY
Agentic-AI safety, including web-agent persuasion attacks.
TOWARD
Web agents that resist social engineering as a default behaviour.
PRACTITIONER · 09
Ryan Othniel Kearns
DPHIL STUDENT
CURRENTLY
The science of evals: how to measure reasoning honestly.
TOWARD
A field where every benchmark publishes its construct validity.
PRACTITIONER · 10
Shreyansh Padarha
DPHIL STUDENT
CURRENTLY
Agentic systems for science, with safety and eval rigour.
TOWARD
Scientific agents auditable enough to act on in real research.
PRACTITIONER · 11
Mia Kussman
MSC STUDENT
CURRENTLY
Studies of human–LLM interaction and LLM evaluation.
TOWARD
Interaction patterns that improve, rather than substitute, human judgement.
PRACTITIONER · 12
Caleb Tan
MSC STUDENT
CURRENTLY
LLM evaluation and reasoning benchmarks.
TOWARD
Reasoning evals that separate genuine inference from recall.
PRACTITIONER · 13
Sebastian Petric
VISITING POLICY FELLOW
CURRENTLY
LLMs applied to financial time series, at the policy boundary.
TOWARD
Honest characterisation of LLM utility in high-stakes financial settings.
PRACTITIONER · 14
Tristan Naidoo
RESEARCH AFFILIATE
CURRENTLY
Public-health AI and LLM evaluations grounded in epidemiology.
TOWARD
Public-health AI that is evaluated like a health intervention.
STEP 05 · WHEN CAN WE SEE WHAT WE LEARNED
Dojo log.
Each entry is something we saw at the board: a paper accepted, a conference reached, an award noted. The log is the lab's memory of cycles closed and evidence kept.
DATEMARKENTRYCATEGORY
MAY 2026◆
今 NOW
Three OxRML papers accepted at ICML 2026 — including a Spotlight
PAPER
APRIL 2026◇
OxRML presenting at ICLR 2026
CONF.
FEBRUARY 2026◆
New paper in Nature Medicine on LLMs as medical assistants
PAPER
FEBRUARY 2026★
Ryan Othniel Kearns wins MSc Thesis Prize
AWARD
DECEMBER 2025◇
OxRML at NeurIPS 2025
CONF.
NOVEMBER 2025◇
OxRML at EMNLP 2025
CONF.
JUNE 2025★
Prof. Adam Mahdi wins Oxford Teaching Excellence Award 2025
AWARD
FEBRUARY 2025◆
New review paper in Information Fusion
PAPER
SEPTEMBER 2024★
Winners of the 2024 PhysioNet Challenge
AWARD
9 ENTRIES · LOGGED IN ORDER OF EVENT
STEP 06 · COACHING KATA
How we work with industry.
We coach teams shipping LLMs into high-stakes settings. Three formats, three cadences, each built around the daily question of what the target condition is and what blocks reaching it.
FORMAT · 01
Workshops for industry teams
On-site sessions for product and ML teams on evaluation, safety, and agent reliability.
Half-day to multi-week formats. For teams shipping LLM products in healthcare, finance, retail, and government.
CADENCE
Half-day to multi-week. Daily standups at the board, weekly review of obstacles.
We work with engineering partners to turn lab work into tools other teams can run.
Evaluation harnesses, safety dashboards, agentic-research platforms. We build them with partners we trust, carrying the research methods through to the code.
CADENCE
Quarterly cycles. Joint roadmaps, shared evals, shipped tooling: research at engineering velocity.
We work with foundations, governments, and corporates who want AI evaluation, safety, and reasoning treated with the same care as the systems they ship.